Data expedition tutorial: UK and US video game magazines
Cédric Lombion - February 3, 2015 in Data Cleaning, HowTo, Spreadsheets, Storytelling, Workshop Methods, Блог, Интернационален

This article is part tutorial, part demonstration of the process I go through to complete a data expedition alone, or as a participant during a School of Data event. Each of the following steps will be detailed: Find, Get, Verify, Clean, Explore, Analyze, Visualize, Publish
Depending on your data, your source or your tools, the order in which you will be going through these steps might be different. But the process is globally the same.
FIND
A data expedition can start from a question (e.g. how polluted are european cities?) or a data set that you want to explore. In this case, I had a question: Has the dynamic of the physical video game magazine market been declining in the past few years ? I have been studying the video game industry for the past few weeks and this is one the many questions that I set myself to answer. Obviously, I thought about many more questions, but it’s generally better to start focused and expand your scope at a later stage of the data expedition.
A search returned Wikipedia as the most comprehensive resource about video game magazines. They even have some contextual info, which will be useful later (context is essential in data analysis).

https://en.wikipedia.org/wiki/List_of_video_game_magazines
GET
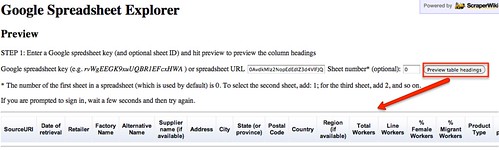
The wikipedia data is formatted as a table. Great! Scraping it is as simple as using the importHTML function in Google spreadsheet. I could copy/paste the table, but that would be cumbersome with a big table and the result would have some minor formatting issues. LibreOffice and Excel have similar (but less seamless) web import features.
importHTML asks for 3 variables: the link to the page, the formatting of the data (table or list), and the rank of the table (or the list) in the page. If no rank is indicated, as seen below, it will grab the first one.

Once I got the table, I do two things to help me work quicker:
- I change the font and cell size to the minimum so I can see more at once
- I copy everything, then go to Edit→Paste Special→Paste values only. This way, the table is not linked to importHTML anymore, and I can edit it at will.
VERIFY
So, will this data really answer my question completely? I do have the basic data (name, founding data, closure date), but is it comprehensive? A double check with the French wikipedia page about video game magazines reveals that many French magazines are missing from the English list. Most of the magazines represented are from the US and the UK, and probably only the most famous. I will have to take this into account going forward.
CLEAN
Editing your raw data directly is never a good idea. A good practice is to work on a copy or in a nondestructive way – that way, if you make a mistake and you’re not sure where, or want to go back and compare to the original later, it’s much easier. Because I want to keep only the US and UK magazines, I’m going to:
- rename the original sheet as “Raw Data”
- make a copy of the sheet and name it “Clean Data”
- order alphabetically the Clean Data sheet according to the “Country” column
- delete all the lines corresponding to non-UK or US countries.

Tip: to avoid moving your column headers when ordering the data, go to Display→Freeze lines→Freeze 1 line.

Some other minor adjustments have to be made, but they’re light enough that I don’t need to use a specialized cleaning tool like Open Refine. Those include:
- Splitting the lines where 2 countries are listed (e.g. PC Gamer becomes PC Gamer UK and PC Gamer US)
- Delete the ref column, which adds no information
- Delete one line where the founding data is missing
EXPLORE
I call “explore” the phase where I start thinking about all the different ways my cleaned data could answer my initial question[1]. Your data story will become much more interesting if you attack the question from several angles.
There are several things that you could look for in your data:
- Interesting Factoids
- Changes over time
- Personal experiences
- Surprising interactions
- Revealing comparisons
So what can I do? I can:
- display the number of magazines in existence for each year, which will show me if there is a decline or not (changes over time)
- look at the number of magazines created per year, to see if the market is still dynamic (changes over time)
For the purpose of this tutorial, I will focus on the second one, looking at the number of magazines created per year Another tutorial will be dedicated to the first, because it requires a more complex approach due to the formatting of our data.
At this point, I have a lot of other ideas: Can I determine which year produced the most enduring magazines (surprising interactions)? Will there be anything to see if I bring in video game website data for comparison (revealing comparisons)? Which magazines have lasted the longest (interesting factoid)? This is outside of the scope of this tutorial, but those are definitely questions worth exploring. It’s still important to stay focused, but writing them down for later analysis is a good idea.
ANALYSE
Analysing is about applying statistical techniques to the data and question the (usually visual) results.
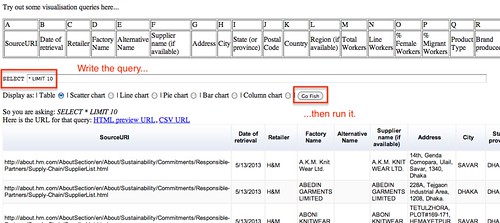
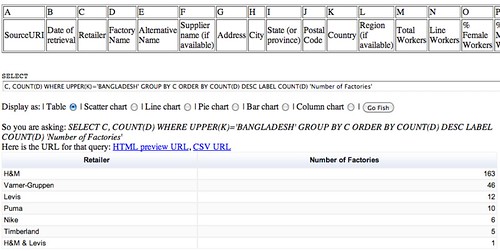
The quickest way to answer our question “How many magazines have been created each year?” is by using a pivot table.
- Select the part of the data that answers the question (columns name and founded)
- Go to Data->Pivot Table
- In the pivot table sheet, I select the field “Founded” as the column. The founding years are ordered and grouped, allowing us to count the number of magazines for each year starting from the earliest.
- I then select the field “Name” as the values. Because the pivot tables expects numbers by default (it tries to apply a SUM operation), nothing shows. To count the number of names associated with each year, the correct operation is COUNTA. I click on SUM and select COUNT A from the drop down menu.

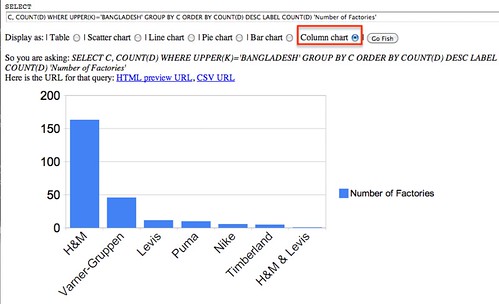
This data can then be visualized with a bar graph.

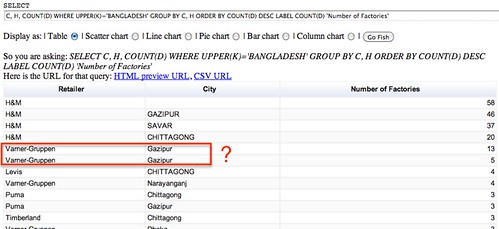
The trendline seems to show a decline in the dynamic of the market, but it’s not clear enough. Let’s group the years by half-decade and see what happens:

The resulting bar chart is much clearer:

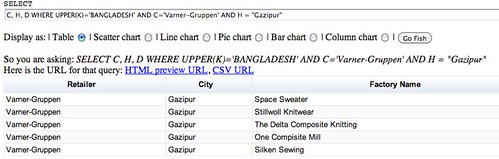
The number of magazines created every half-decade decreases a lot in the lead up to the 2000s. The slump of the 1986-1990 years is perhaps due to a lagging effect of the North american video game crash of 1982-1984
Unlike what we could have assumed, the market is still dynamic, with one magazine founded every year for the last 5 years. That makes for an interesting, nuanced story.
VISUALISE
In this tutorial the initial graphs created during the analysis are enough to tell my story. But if the results of my investigations required a more complex, unusual or interactive visualisation to be clear for my public, or if I wanted to tell the whole story, context included, with one big infographic, it would fall into the “visualise” phase.
PUBLISH
Where to publish is an important question that you have to answer at least once. Maybe the question is already answered for you because you’re part of an organisation. But if you’re not, and you don’t already have a website, the answer can be more complex. Medium, a trendy publishing platform, only allows images at this point. WordPress might be too much for your need. It’s possible to customize the Javascript of tumblr posts, so it’s a solution. Using a combination of Github Pages and Jekyll, for the more technically inclined, is another. If a light database is needed, take a look at tabletop.js, which allows you to use a google spreadsheet as a quasi-database.
Any data expedition, of any size or complexity, can be approached with this process. Following it helps avoiding getting lost in the data. More often than not, there will be a need to get and analyze more data to make sense of the initial data, but it’s just a matter of looping the process.
[1] I formalized the “explore” part of my process after reading the excellent blog from MIT alumni Rahoul Bhargava http://datatherapy.wordpress.com
![]()