Having access to geo-data is one thing, quickly sketching it on to a map is another. In this post, we look at how you can use OpenRefine to take some tabular data and export it in a format that can be quickly visualised on an interactive map.
At the School of Data, we try to promote an open standards based approach: if you put your data into a standard format, you can plug it directly into an application that someone else has built around that standard, confident in the knowledge that it should “just work”. That’s not always true of course, but we live in hope.
In the world of geo-data – geographical data – the geojson standard defines a format that provides a relatively lightweight way of representing data associated with points (single markers on a map), lines (lines on a map) and polygons (shapes or regions on a map).
Many applications can read and write data in this format. In particular, Github’s gist service allows you to paste a geojson data file into a gist, whereupon it will render it for you (Gist meets GeoJSON).
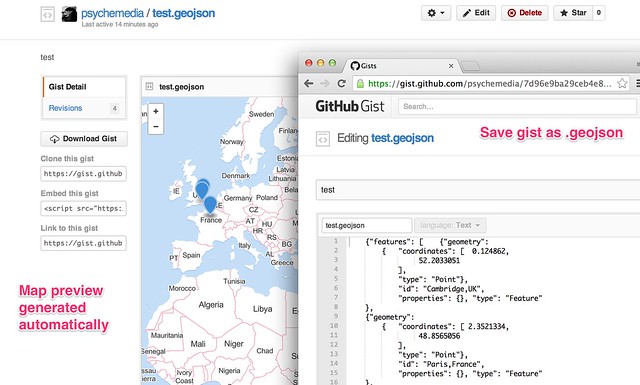
So how can we get from some tabular data that looks something like this:
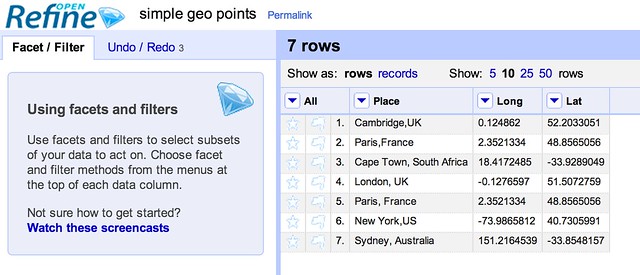
Into the geojson data, which looks something like this?
{"features": [ {"geometry":
{ "coordinates": [ 0.124862,
52.2033051
],
"type": "Point"},
"id": "Cambridge,UK",
"properties": {}, "type": "Feature"
},
{"geometry":
{ "coordinates": [ 151.2164539,
-33.8548157
],
"type": "Point"},
"id": "Sydney, Australia",
"properties": {}, "type": "Feature"
}], "type": "FeatureCollection"}
[We’re assuming we have already geocoded the location to get latitude and longitude co-ordinates for it. To learn how to geocode your own data, see the School of Data lessons on geocoding or this tutorial on Geocoding Using the Google Maps Geocoder via OpenRefine].
One approach is to use OpenRefine [openrefine.org]. OpenRefine allows you to create your own custom export formats, so if we know what the geojson is supposed to look like (and the standard tells us that) we can create a template to export the data in that format.
Steps to use Open Refine:
Locate the template export tool is in the OpenRefine Export drop-down menu:
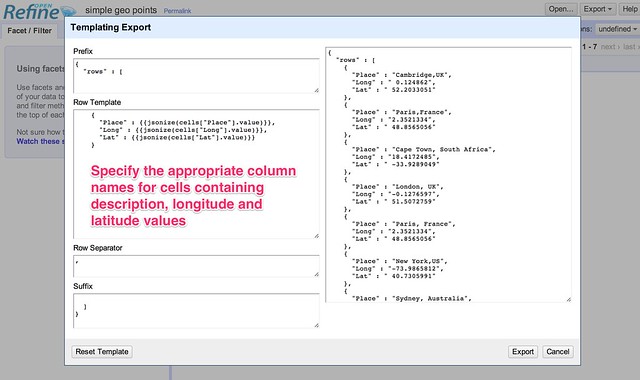
Define the template for our templated export format. The way the template is applied is to create a standard header (the prefix), apply the template to each row, separating the templated output for each row by a specified delimiter, and then adding a standard footer (the suffix).
Once one person has worked out the template definition and shared it under an open license, the rest of us can copy it, reuse it, build on it, improve it, and if necessary, correct it…:-) The template definitions I’ve used here are a first attempt and represent a proof-of-concept demonstration: let us know if the approach looks like it could be useful and we can try to work it up some more.
It would be useful if OpenRefine supported the ability to save and import different template export configuration files, perhaps even allowing them to be imported from and save to a gist. Ideally, a menu selector would allow column names to be selected from the current data file and then used in template.
Here are the template settings for template that will take a column labelled “Place”, a column named “Lat” containing a numerical latitude value and a column named “Long” containing a numerical longitude and generate a geojson file that allows the points to be rendered on a map.
Prefix:
{"features": [
Row template:
{"geometry":
{ "coordinates": [ {{cells["Long"].value}},
{{cells["Lat"].value}}
],
"type": "Point"},
"id": {{jsonize(cells["Place"].value)}},
"properties": {}, "type": "Feature"
}
Row separator:
,
Suffix:
], "type": "FeatureCollection"}
This template information is also available as a gist: OpenRefine – geojson points export format template.
Another type of data that we might want to render onto a map is a set of markers that are connected to each other by lines.
For example, here is some data that could be seen as describing connections between two places that are mentioned on the same data row:
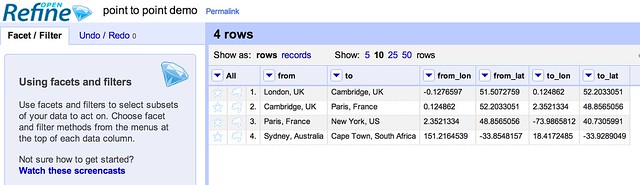
The following template generates a place marker for each place name, and also a line feature that connects the two places.
Prefix:
{"features": [
Row template:
{"geometry":
{ "coordinates": [ {{cells["from_lon"].value}},
{{cells["from_lat"].value}}
],
"type": "Point"},
"id": {{jsonize(cells["from"].value)}},
"properties": {}, "type": "Feature"
},
{"geometry":
{ "coordinates": [ {{cells["to_lon"].value}},
{{cells["to_lat"].value}}
],
"type": "Point"},
"id": {{jsonize(cells["to"].value)}},
"properties": {}, "type": "Feature"
},
{"geometry": {"coordinates":
[[{{cells["from_lon"].value}}, {{cells["from_lat"].value}}],
[{{cells["to_lon"].value}}, {{cells["to_lat"].value}}]],
"type": "LineString"},
"id": null, "properties": {}, "type": "Feature"}
Row separator:
,
Suffix:
], "type": "FeatureCollection"}
If we copy the geojson output from the preview window, we can paste it onto a gist to generate a map preview that way, or test it out in a geojson format checker such as GeoJSONLint:
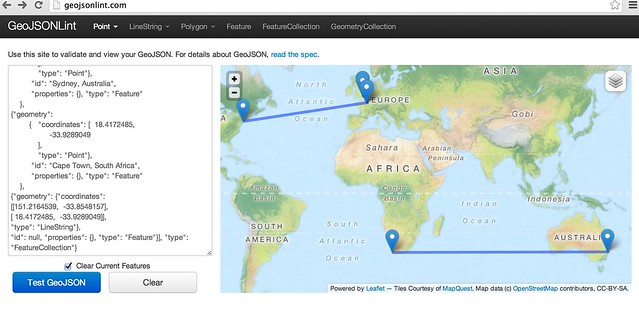
I have pasted a copy of the OpenRefine template I used to generate the “lines connecting points” geojson here: OpenRefine export template: connected places geojson.
Finally, it’s worth noting that if we can define a standardised way of describing template generated outputs from tabular datasets, libraries can be written for other programming tools or languages, such as R or Python. These libraries could read in a template definition file (such as the gists based on the OpenRefine export template definitions that are linked to above) and then as a direct consequence support “table2format” export data format conversions.
Which makes me wonder: is there perhaps already a standard for defining custom templated export formats from a tabular data set?


















{kind=link}