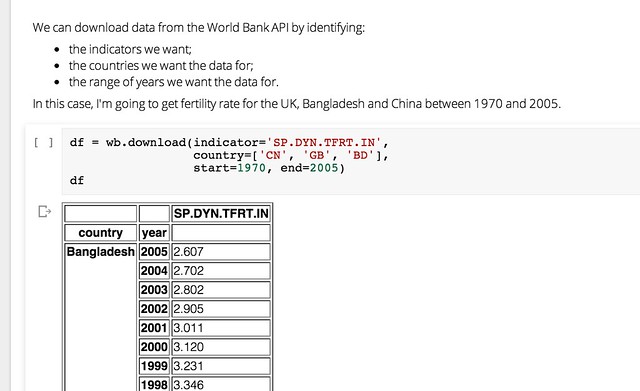
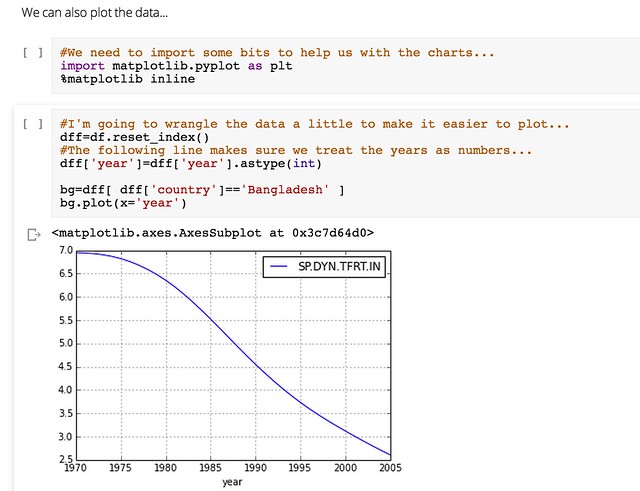
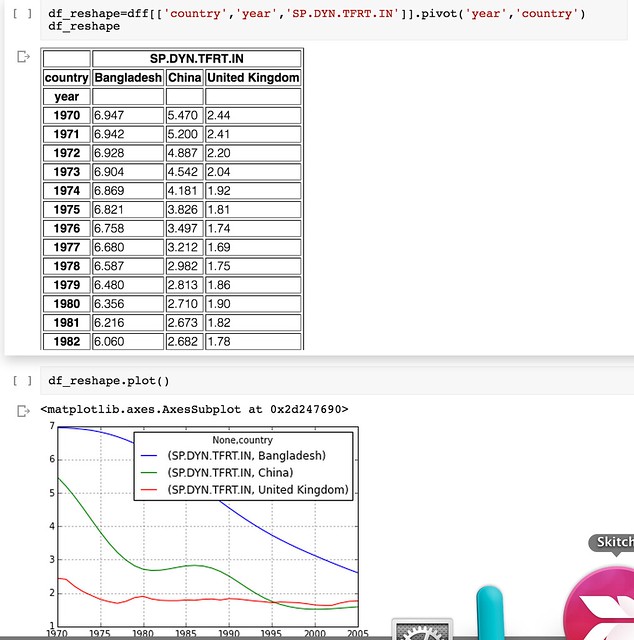
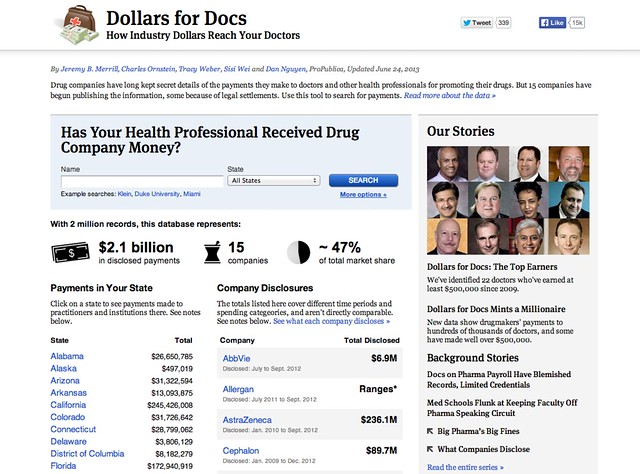
Data for Social Change in South Africa
Hannah Williams - September 29, 2014 in Community, Data Blog, Data Expeditions, Data for CSOs, Data Journalism, School_Of_Data
We recently kicked off our first local Code for South Africa School of Data workshops in Johannesburg and Cape Town for journalists and civil society respectively.
I arrived in the vibrant Maboneng district in central Johannesburg excited (and a little nervous) about helping my fellow school of Data Fellow Siyabonga facilitate our first local workshop with media organisations The Con and Media Monitoring Africa. Although I’ve attended a data workshop this was my first experience of being on the other end and it was an incredible learning experience. Siya did a fantastic job of leading the organisations in defining and conceptualising their data projects that they’ll be working on over the course of the rest of the year and I certainly borrowed and learned a lot from his workshop format.
It was great to watch more experienced facilitators, Jason from Code for South Africa and Michael from The School of Data, work their magic and share their expert knowledge on more advanced tools and techniques for working with and presenting data and see the attendees eyes light up at the possibilities and potential applications of their data.

Johannesburg sunset at the workshop venue
A few days later we found ourselves back in the thick of things giving the second workshop in Cape Town for civil society organisations Black Sash and Ndifuna Ukwazi. I adapted Siyabonga’s workshop format slightly, shifting the emphasis from journalism to advocacy and effecting social change for our civil society attendees.
We started off examining the broader goals of the organisation and worked backwards to identify where and how data can help them achieve their goals, as data for data’s sake in isolation is meaningless and our aim is to help them produce meaningful data projects that make a tangible contribution to their goals.

The team from Ndifuna Ukwazi at work
We then covered some general data principles and skills like the data pipeline and working with spreadsheets and easy-to-use tools like Datawrapper and Infogr.am, as well as some more advanced (and much needed) data cleaning using Open Refine as well as scraping data using Tabula which the teams found extremely useful, having been manually typing out information from pdfs up until this point.
Both organisations arrived with the data they wanted to work with at hand and it immediately became apparent that it needed a lot of cleaning. The understanding the organisations gained around working with data allowed them to reexamine the way they collect and source data, particularly for Black Sash who realised they need to redesign their surveys they use. This will be an interesting challenge over the next few months as the survey re-design will still need to remain compatible with the old survey formats to be useful for comparison and analysis and I hope to be able to draw on the experience and expertise of the School of Data network to come up with a viable solution.

Siya working his magic with the Black Sash team
By the end of the workshop both organisations had produced some visualisations using their data and had a clear project plan of how they want to move forward, which I think is a great achievement! I was blown away by the enthusiasm and work ethic of the attendees and I’m looking forward to working with them over the next few months and helping them produce effective data projects that will contribute to more inclusive, equitable local governance.
![]()